One Model, One Call: Running NVIDIA Nemotron 3 Nano Omni on GMI Cloud
NVIDIA Nemotron 3 Nano Omni is a 30B-parameter open multimodal model that processes text, images, video, and audio in a single reasoning loop, now available on GMI Cloud. This post covers the architecture, real-world use cases, and a live drone pothole-detection demo.
April 28, 2026
.png)
Every real-world AI agent needs to see, hear, and read. Until now, building one meant assembling three separate models, three pipelines, and three places for something to break. A vision model for images. A speech model for audio. A language model to make sense of it all. Then you stitch them together, hope the context doesn't get lost between hops, and watch your latency stack up.
NVIDIA Nemotron 3 Nano Omni changes that. It launched today, April 28, and it is now available to run on GMI Cloud.
What it actually is
Nemotron 3 Nano Omni is an open, multimodal foundation model. You send it text, images, video, or audio. It responds with text. One model, one reasoning loop. The weights are on Hugging Face, it runs as an NVIDIA NIM on build.nvidia.com, and you can hit it today through GMI Cloud.
The full model name is Nemotron-3-Nano-Omni-30B-A3B-Reasoning. It is 30 billion parameters total, but only about 3 billion activate per forward pass thanks to a Mixture-of-Experts (MoE) architecture. That means you get strong reasoning at a fraction of the inference cost of a dense 30B model.
A few things worth knowing upfront:
• Context window: 256k tokens. Long documents, long videos, multi-step agent workflows in a single prompt.
• Quantization: FP8 and NVFP4 supported out of the box.
• Hardware: Runs on NVIDIA H100, H200, B200, A100, L40S GPUs, and DGX Spark systems.
• License: Open weights, open data, open recipes. You can fine-tune it, deploy it, and build on it.
• Output: Text only. Despite the "Omni" name, it is a perception-and-reasoning engine, not a generator of images or audio. Set that expectation with your team before you ship.
Why the architecture matters for builders
Most multimodal models process modalities separately and then merge the outputs. Omni does not work that way.
It uses 3D convolutional layers (Conv3D) to process video as a volume in space and time, rather than as a sequence of individual frames. This is the key insight from recent video LLM research: models that jointly understand spatiotemporal context outperform those that analyze frames in isolation, especially for detecting changes, patterns, and failure moments over time (VideoRefer Suite, Yuan et al., CVPR 2025).
Combined with Efficient Video Sampling (EVS), the model focuses compute on the most dynamic parts of a video rather than scanning every frame. That combination delivers roughly 9x lower compute for video tasks compared to standard frame-by-frame approaches, according to NVIDIA.
The underlying LLM backbone is Nemotron 3 Nano, which uses a hybrid Mamba-Transformer architecture. Mamba layers replace most of the expensive self-attention blocks. The result is a constant memory state during generation instead of a linearly growing KV cache, which is the main reason the model can sustain high throughput at long context lengths (NVIDIA Nemotron 3 Technical Report, arXiv 2512.20856).
In practice: Nemotron 3 Nano Omni does not just see a moment in time. It watches what happens.
What you can build with it today
Here are three use cases that represent what the model actually does well right now.
Computer use agent
Feed it a screen recording of a user navigating your product. Ask it what the user tried to do, what went wrong, and what the UI should say next. The output reads like a senior product manager wrote it. It uses the same perception loop whether the video is 5 seconds or 5 minutes.
Document intelligence
Drop in a PDF with charts, tables, and scanned text. Ask it to extract revenue by segment from a chart and cross-reference the management commentary. It handles mixed-media documents in a single call without needing a separate OCR pipeline.
Audio and video understanding
Record a voice memo describing a support issue or a field observation. Omni transcribes, understands context, and structures the output as a ticket, a report, or a JSON object. The Parakeet speech encoder processes audio natively within the same model.
Our demo: detecting potholes from a drone video
We wanted to test Nemotron 3 Nano Omni on something more physical than a screen recording or a document, so we used drone footage from a street survey.
The prompt asked the model to analyze each sampled frame, identify visible road surface issues, classify the type of defect, estimate severity, describe where it appeared in the scene, and return the result in a structured JSON format that we could use downstream.

What made the demo interesting was not just whether the model could identify potholes. A specialized object detection model can do that. What we wanted to test was whether a single multimodal model could look at a moving aerial scene, understand what was happening over time, reason about severity from visual context, describe location in natural language, and return structured output that could be used in a real workflow.
To make that practical, we built a lightweight pipeline around the model. Instead of sending the full video directly, we sampled frames at an adaptive rate based on clip length and sent them through GMI Cloud’s OpenAI-compatible API. From there, we added a few simple post-processing steps to normalize coordinates, remove obvious false positives, and keep the annotations stable as the drone moved across the scene.
For the output layer, we used OpenCV to draw labeled overlays on the video and export an annotated MP4. We also generated a PDF report with a summary of the detected issues and cropped examples for review.
That distinction matters. The model handled the perception and reasoning, but a thin layer of application logic made the results usable and easier to present. No custom training, no dedicated pothole dataset, and no large detection pipeline. Just a multimodal model plus a small amount of practical engineering.
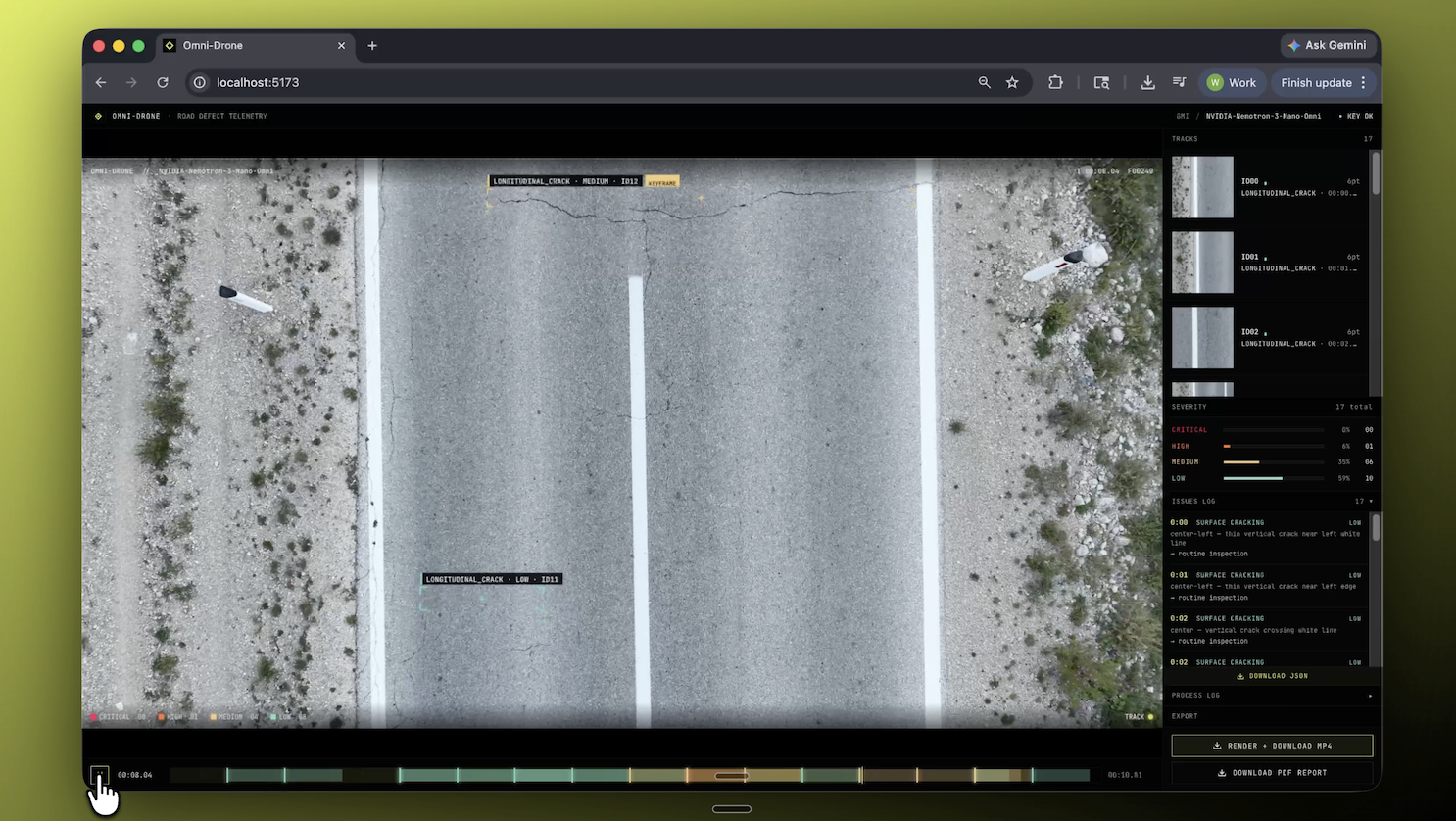
For us, that was the real takeaway. This was not a research prototype that needed weeks of tuning. It was a usable inspection workflow built quickly with standard tools.
Running it on GMI Cloud
GMI Cloud runs NVIDIA H100 and H200 GPUs with an OpenAI-compatible API. You can be hitting the model in under five minutes.
curl https://api.gmi-serving.com/v1/chat/completions \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer $API_KEY' \
--data '{
"model": "nvidia/NVIDIA-Nemotron-3-Nano-Omni",
"messages": [
{"role": "system", "content": "You are a helpful AI assistant"},
{"role": "user", "content": "List 3 countries and their capitals."}
],
"temperature": 0,
"max_completion_tokens": 500
}'
No fine-tuning. No pipeline setup. Swap the image for an audio file or a video clip and update the prompt.
Things to know before you go to production
Nemotron 3 Nano Omni is your perception layer. It understands video, audio, images, and documents natively, but output is text. Turning its structured results into visual overlays, dashboards, or annotated reports is a second step, and a lightweight one. A few lines of OpenCV or any rendering library gets you there.
On the infrastructure side, the A3B active parameter count makes this model lean to run. That said, MoE routing behavior varies by GPU configuration, so test on your actual hardware before quoting throughput numbers to stakeholders. Performance on H100 and H200 will differ from smaller setups.
In addition to winning multiple leaderboards for complex document intelligence and video and audio understanding, NVIDIA conducted evaluations and found that if you use this model, an AI system can achieve 9x higher throughput for video use cases and ~7x higher throughput for multi-document use cases than other open omni models with the same interactivity, resulting in lower cost and better scalability without sacrificing responsiveness.
Get started
Nemotron 3 Nano Omni is available today on GMI Cloud. You can access it through the GMI console at console.gmicloud.ai or hit the API directly using the quickstart above.
The model is fully open and available on Hugging Face, as well as packaged and optimized as an NVIDIA NIM microservice on build.nvidia.com if you want to compare deployments.
If you build something with it, share it in the GMI Discord . We are especially curious to see what people do beyond the expected use cases.
References
1. NVIDIA Nemotron 3 Technical Report. "NVIDIA Nemotron 3: Efficient and Open Intelligence." arXiv:2512.20856, December 2025.
2. VideoRefer Suite. "Advancing Spatial-Temporal Object Understanding with Video LLM." CVPR 2025.
Roan Weigert
Developer Relations
Build AI Without Limits
GMI Cloud helps you architect, deploy, optimize, and scale your AI strategies
