
Announcing DeepSeek-V3.1 on GMI Cloud
DeepSeek-V3.1 is the latest upgrade to DeepSeek’s flagship open-weight LLM. The Instruct model is now fully integrated into the GMI Cloud inference engine. It introduces a hybrid inference architecture—supporting both fast, direct responses (“Non-Think” mode) and deep, multi-step reasoning (“Think” mode)—while enabling 128K-token context handling, open-source accessibility, and better integration for tool-using AI agents.
What’s New in DeepSeek-V3.1
Hybrid Inference: Think & Non-Think Modes
DeepSeek-V3.1 introduces a dual-mode system:
- Non-Thinking Mode → Fast, concise answers for efficiency
- Thinking Mode → Deep, step-by-step reasoning for complex workflows
Users can toggle modes via the DeepThink button on the app or web interface.
API & Integration Enhancements
Two Endpoints for Flexibility
- deepseek-chat: optimized for non-thinking responses
- deepseek-reasoner: built for reasoning-intensive tasks
Integration Upgrades
- Supports 128K-token context windows for both endpoints
- Adds Anthropic-style API formatting
- Enables Strict Function Calling (Beta) for reliable, agent-driven workflows
Model Architecture Upgrades
Long-Context Pretraining
- Expanded 32K-phase training by 10× to 630B tokens
- Expanded 128K-phase training by 3.3× to 209B tokens
Efficient Precision Format
Uses UE8M0 FP8 for faster processing speeds and compatibility with micro-scaling formats.
Open-Source Release
Both V3.1 base weights and the full model weights are publicly available on Hugging Face.
Performance Boosts & Agent Capabilities
- Smarter Tool Use → Better multi-step reasoning, API integration, and autonomous workflows
- Faster “Thinking” Mode → Matches DeepSeek-R1-0528’s accuracy but responds more quickly
- Improved Agent Behaviors → More reliable search, integration, and orchestration of external tools
Performance Benchmarks
DeepSeek-V3.1 consistently outperforms earlier versions across code, reasoning, and search benchmarks, showing major gains in SWE-bench, multilingual tasks, and complex search. It also produces longer, higher-quality outputs on reasoning-heavy benchmarks like AIME 2025 and GPQA.
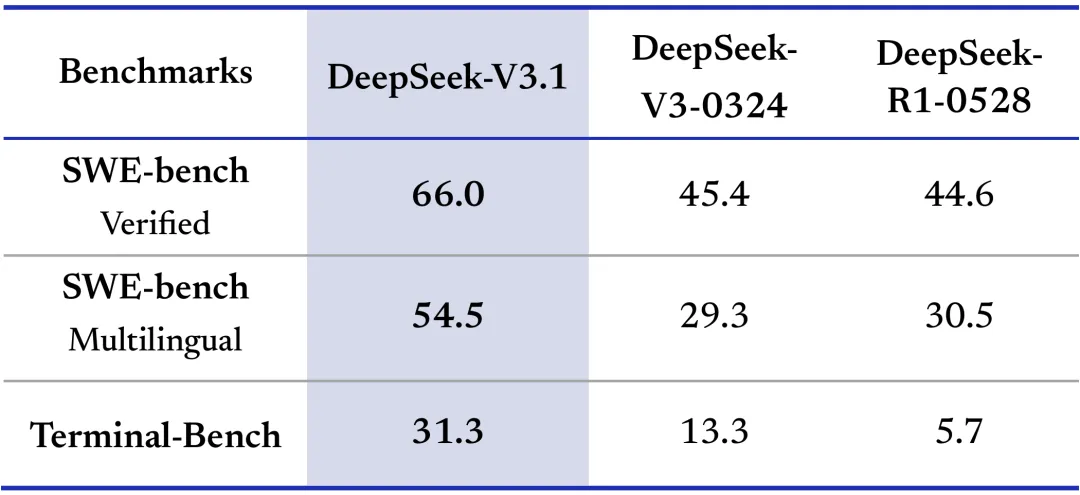

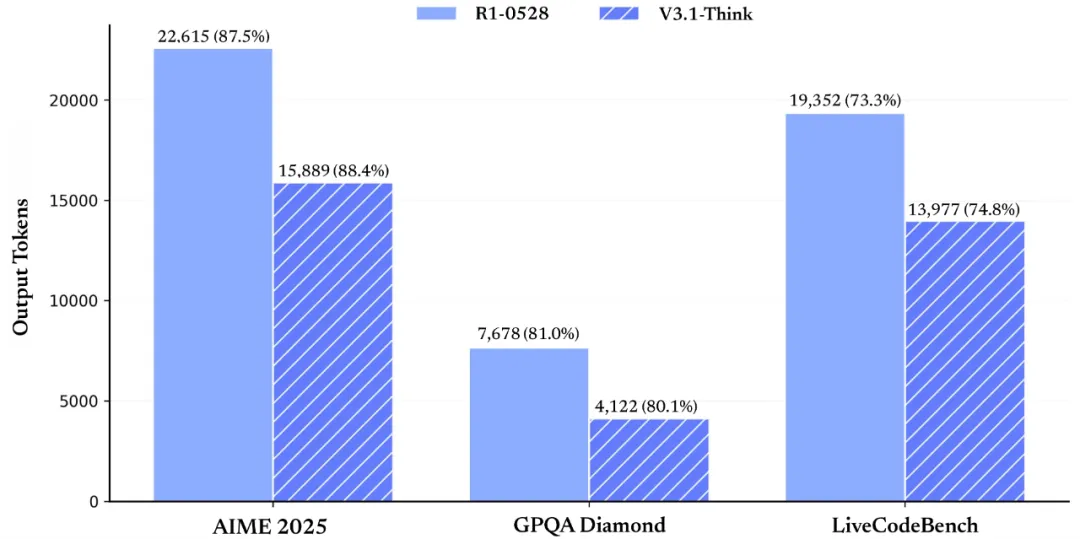
Run DeepSeek-V3.1 on GMI Cloud
You can deploy DeepSeek-V3.1 immediately through our inference engine by following the instructions here.
GMI Cloud provides the infrastructure, tooling, and support needed to deploy DeepSeek-V3.1 at scale. Our inference engine is optimized for large-token throughput and ease of use, enabling rapid integration into production environments
With GMI Cloud, you can:
- Serve DeepSeek-V3.1 via optimized, high-throughput inference backend
- Configure models for batch, streaming, or interactive inference
- Integrate with prompt management, RAG pipelines, and eval tooling
- Connect via simple APIs without additional DevOps effort
- Scale with usage-based pricing and full visibility into performance
At GMI Cloud, we’re excited to offer access to DeepSeek-V3.1 because it delivers open-weight flexibility with cutting-edge reasoning capabilities, empowering developers to build research assistants, knowledge engines, and long-memory AI systems without sacrificing speed or cost efficiency.
Pricing & Availability
DeepSeek-V3.1 is available today via:
- Web app with DeepThink toggle
- Updated API endpoints
- GMI Cloud deployment for optimized compute environments
- $0.9/$0.9 with GMI Cloud
DeepSeek-V3.1 at a Glance
| Feature | Highlight |
|---|---|
| Modes | Hybrid inference: Think & Non-Think |
| Context Capacity | Up to 128K tokens |
| Pretraining Scale | 630B tokens (32K) + 209B tokens (128K) |
| Precision Format | UE8M0 FP8 for efficient inference |
| Pricing | $0.9 / $0.9 with GMI Cloud |
Why It Matters
DeepSeek-V3.1 represents a strategic evolution for AI development:
- Technically, it brings agent-ready inference and long-context handling to open-source models.
- Politically, its Chinese chip optimization signals an alignment with domestic hardware ecosystems, an important step amid U.S.-China tech tensions.
Practically, developers gain access to a powerful, flexible model that can toggle between speed and deep reasoning—and now, with GMI Cloud integration, they can scale it effortlessly in production.
Build AI Without Limits
GMI Cloud helps you architect, deploy, optimize, and scale your AI strategies
